介绍
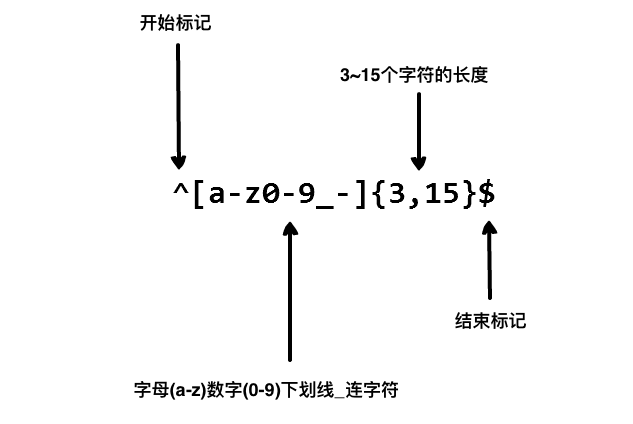
^[0-9]+abc$
^为匹配输入字符串的开始位置。[0-9]+匹配多个数字,[0-9]匹配单个数字,+匹配一个或者多个。abc$匹配字母abc并以abc结尾,$为匹配输入字符串的结束位置。
语法
非打印字符
\cx匹配由x指明的控制字符。例如,\cM匹配一个Control-M或回车符。x的值必须为A-Z或a-z之一。否则,将c视为一个原义的 ‘c’ 字符。\f匹配一个换页符。等价于\x0c和\cL。\n匹配一个换行符。等价于\x0a和\cJ。\r匹配一个回车符。等价于\x0d和\cM。\s匹配任何空白字符,包括空格、制表符、换页符等等。等价于[ \f\n\r\t\v]。注意 Unicode 正则表达式会匹配全角空格符。\S匹配任何非空白字符。等价于[^ \f\n\r\t\v]。\t匹配一个制表符。等价于\x09和\cI。\v匹配一个垂直制表符。等价于\x0b和\cK。
特殊字符
$匹配输入字符串的结尾位置。如果设置了 RegExp 对象的 Multiline 属性,则$也匹配'\n'或'\r'。要匹配$字符本身,请使用\$。 ( ) 标记一个子表达式的开始和结束位置。子表达式可以获取供以后使用。要匹配这些字符,请使用 ( 和 )。*匹配前面的子表达式零次或多次。要匹配 * 字符,请使用\*。+匹配前面的子表达式一次或多次。要匹配 + 字符,请使用\+。.匹配除换行符 \n 之外的任何单字符。要匹配 . ,请使用 . 。[标记一个中括号表达式的开始。要匹配 [,请使用\[。?匹配前面的子表达式零次或一次,或指明一个非贪婪限定符。要匹配?字符,请使用\?。\将下一个字符标记为或特殊字符、或原义字符、或向后引用、或八进制转义符。例如, ‘n’ 匹配字符 ‘n’。'\n'匹配换行符。序列'\\'匹配"\",而'\('则匹配"("。^匹配输入字符串的开始位置,除非在方括号表达式中使用,当该符号在方括号表达式中使用时,表示不接受该方括号表达式中的字符集合。要匹配^字符本身,请使用\^。{标记限定符表达式的开始。要匹配{,请使用\{。|指明两项之间的一个选择。要匹配|,请使用\|。
限定符
*匹配前面的子表达式零次或多次。例如,zo*能匹配"z"以及"zoo"。*等价于{0,}。+匹配前面的子表达式一次或多次。例如,'zo+'能匹配"zo"以及"zoo",但不能匹配"z"。+等价于{1,}。?匹配前面的子表达式零次或一次。例如,"do(es)?"可以匹配"do"、"does"中的"does"、"doxy"中的"do"。?等价于{0,1}。{n}n是一个非负整数。匹配确定的n次。例如,'o{2}'不能匹配"Bob"中的'o',但是能匹配"food"中的两个o。{n,}n是一个非负整数。至少匹配n次。例如,’o{2,}’ 不能匹配 “Bob” 中的 ‘o’,但能匹配 “foooood” 中的所有 o。’o{1,}’ 等价于 ‘o+’。’o{0,}’ 则等价于 ‘o*‘。{n,m}m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。例如,”o{1,3}” 将匹配 “fooooood” 中的前三个 o。’o{0,1}’ 等价于 ‘o?’。请注意在逗号和两个数之间不能有空格。
*、+限定符都是贪婪的,因为它们会尽可能多的匹配文字,只有在它们的后面加上一个?就可以实现非贪婪或最小匹配。
定位符
^匹配输入字符串开始的位置。如果设置了 RegExp 对象的Multiline属性,^还会与\n或 `r` 之后的位置匹配。$匹配输入字符串结尾的位置。如果设置了 RegExp 对象的Multiline属性,$还会与\n或\r之前的位置匹配。\b匹配一个单词边界,即字与空格间的位置。\B非单词边界匹配。
示例
1
var str = "http://www.runoob.com:80/html/html-tutorial.html";
var patt1 = /(\w+):\/\/([^/:]+)(:\d*)?([^# ]*)/;
arr = str.match(patt1);
for (var i = 0; i < arr.length ; i++) {
document.write(arr[i]);
document.write("<br>");
}
将正则表达式应用到上面的 URI,各子匹配项包含下面的内容:
- 第一个括号子表达式包含
http - 第二个括号子表达式包含
www.runoob.com - 第三个括号子表达式包含
:80 - 第四个括号子表达式包含
/html/html-tutorial.html
var strMatch = `-rw-r--r--. 1 root root 114769 Apr 26 15:39 CN_CM_SHANGHAI_24709063_M.mtl
-rw-r--r--. 1 root root 2879642 Apr 26 15:39 CN_CM_SHANGHAI_2470190623_Q.obj`;
2
截取字符串中以CN_开头.mtl结尾的部分(包含开头和结尾)
var matchReg = /CN_.*?\.mtl/gi;
console.log(strMatch.match(matchReg));
//输出 CN_CM_SHANGHAI_24709063_M.mtl
.表示除换行符\n之外的任意字符*匹配前面的子表达式0次或多次?匹配前面的子表达式零次或一次,或指明一个非贪婪限定符\.是匹配.g全局匹配i不区分大小写
截取字符串以CN_开头,以.mtl之前的内容结尾
var matchReg = /CN_.*?(?=.mtl)/gi;
console.log(strMatch.match(matchReg));
//输出CN_CM_SHANGHAI_24709063_M
(?=.mtl)表示以.mtl结尾的前面字符串,不包含.mtl
截取字符串CN_和.mtl之间的内容(不包含CN_和.mtl)
var matchReg = /(?<=CN_).*?(?=.mtl)/;
console.log(strMatch.match(matchReg));
//输出 CM_SHANGHAI_24709063_M
(?<=CN_)表示获取CN_之后的字符串。不包含CN_
获得CN_之后(不包括CN_), .mtl之前的。(包括.mtl)的字符串方法
var matchReg = /(?<=CN_).*?\.mtl/;
console.log(strMatch.match(matchReg));
//输出 CM_SHANGHAI_24709063_M.mtl
输出以CN_开头,.mtl或者.obj结尾的字符串
ar matchReg = /CN_.*?(.mtl|.obj)/;
console.log(strMatch.match(matchReg));
//输出 CN_CM_SHANGHAI_24709063_M.mtl和CN_CM_SHANGH
输出以CN_开头,以.mtl或者.obj结尾之前的内容
var matchReg = /CN_.*?(?=(.mtl|.obj))/;
console.log(strMatch.match(matchReg));
//输出 CN_CM_SHANGHAI_24709063_M和CN_CM_SHANGHAI_2